【工事中】kindで構築したKubernetesクラスタにKubeFlowを構築する
目次
- kubectlを導入する
- kindを導入
前提
ネイティブでUbuntu 24.04 LTSを導入していることを前提とします。 なお、私はデスクトップ版で導入したので、もしかしたらサーバ版では一部コマンドでエラーになるかもしれません。 その他の環境は以下の通りです。
- Ubuntu 24.04 LTS Desktop
- Docker version 27.4.1, build b9d17ea
- 実行ユーザ名は
ubuntuとする
kubectlを導入する
snap install kubectl --classic
kindを導入する
READMEを参考に導入していきます。
[ $(uname -m) = x86_64 ] && curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.26.0/kind-$(uname)-amd64
KubeFlowを導入する
執筆時点で最新のv1.9.1を導入します。 ちなみに、DockerをでRootless Dockerで動かしている場合、はkindコマンドにsudoは不要です。
kindでクラスタを構築する。
cat <<EOF | kind create cluster --name=kubeflow --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
image: kindest/node:v1.31.0@sha256:53df588e04085fd41ae12de0c3fe4c72f7013bba32a20e7325357a1ac94ba865
kubeadmConfigPatches:
- |
kind: ClusterConfiguration
apiServer:
extraArgs:
"service-account-issuer": "kubernetes.default.svc"
"service-account-signing-key-file": "/etc/kubernetes/pki/sa.key"
EOF
この後KubeFlowを導入するためにkubectを使います。
kubectlを使うためにはkindで構築したクラスタの証明書を含む設定ファイルを書き出す必要があります。
通常は${HOME}/.kube/configに配置して使用するのですが、今回は設定ファイルを使い捨てにするために/tmp/kubeflow-configに書き出します。
kind get kubeconfig --name kubeflow > /tmp/kubeflow-config export KUBECONFIG=/tmp/kubeflow-config
imageをpullするためにDockerのログイン情報を書き出します。 いまいちこの手順の
docker login
kubectl create secret generic regcred \
--from-file=.dockerconfigjson=/home/ubuntu/.docker/config.json \
--type=kubernetes.io/dockerconfigjson
ドキュメントに書かれている通りに実行するとエラーとなったので、その代わりissueから発掘したコマンドを試しました。
while ! kustomize build example | kubectl apply --server-side --force-conflicts -f -; do echo "Retrying to apply resources"; sleep 20; done
実行後、10分くらいはすべてのPodが立ち上がらないため、待つ必要があります。 以下のコマンドを実行して最終的に全てのポッドがErrorやCrash Loop Backではなく、Runningになるのを待ちます。
kubectl get pods -A
KubeFlowをサーバ外からアクセスできるようにする
[論文紹介]Unsupervised Sound Separation Using Mixture Invariant Training
久々に、ブログを書く気になったので、最近読んでいて面白かった「Unsupervised Sound Separation Using Mixture Invariant Training」についてまとめる。 特に記載がなければ論文中の図表は以下を参照しています。
[1] S. Wisdom, E. Tzinis, H. Erdogan, R. J. Weiss, K. Wilson, and J. R. Hershey, “Unsupervised sound separation using mixture invariant training,” Adv. Neural Inf. Process. Syst., vol. 2020-Decem, no. NeurIPS, 2020. https://proceedings.neurips.cc/paper/2020/file/28538c394c36e4d5ea8ff5ad60562a93-Paper.pdf
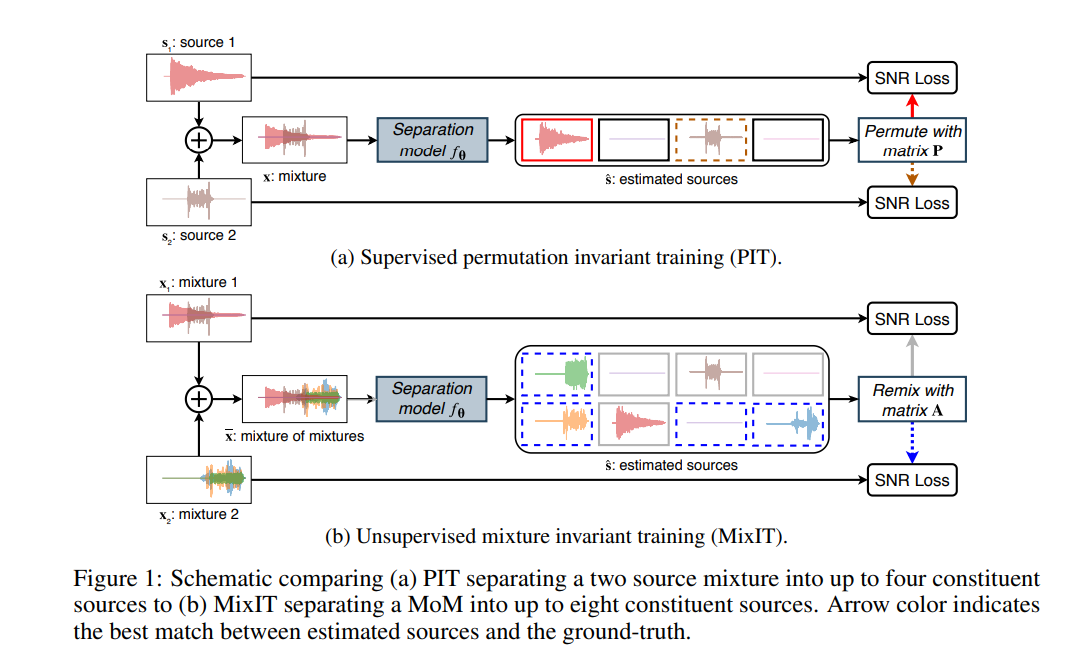
もうちょっと自分の理解を備忘録としてまとめたい。
そもそもこの論文なに?
Blind Source SeparationとかBlind Singnal Separationというジャンルの論文です。 Mixされた信号からMixする前の信号(原信号)を分離することを目標としていて、特に、この論文ではUnsupervised learningで実現することを目標としています。 UnsupervisedなBlind Source Separation問題で典型的な問題としてモデルの入力であるMixされた信号の原信号がどのようになっているかは知ることができません。 そのため学習のさせ方そのものを工夫しているのが本論文です。
学習のさせ方
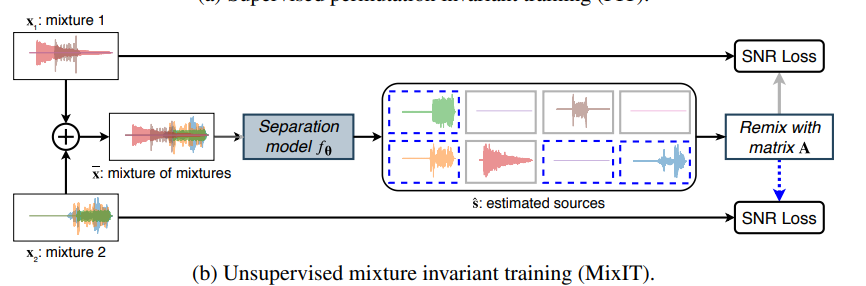 一枚目にも書いていますがUnsupervisedな部分だけ再掲。
要は学習データ2個の和をとった信号をモデルに入力して、出力はその信号を分離した信号になります。
分離する個数は感覚で決めることになると思います。
一般的なデータの入出力テンソルの形状は入力が(N, 1)、出力が(N, C)となります(特にNは信号の系列長、Cは分離する信号の数=チャネル数)。
一枚目にも書いていますがUnsupervisedな部分だけ再掲。
要は学習データ2個の和をとった信号をモデルに入力して、出力はその信号を分離した信号になります。
分離する個数は感覚で決めることになると思います。
一般的なデータの入出力テンソルの形状は入力が(N, 1)、出力が(N, C)となります(特にNは信号の系列長、Cは分離する信号の数=チャネル数)。
ここで、1つ問題があります。 分離した信号の出力は出力信号の入れ替わりが起こり得ます。
例えば、このとき、出力の各チャネルのどこに何を分離するかはSupervised Learningでは一意に決めることができますが(例えば環境音+人の話し声なら、1チャネル目に環境音、2チャネル目に人の話し声を入れたデータを学習データとして用意して誤差計算を行う)、Unsupervised Learningでは入力データがどのような音をMixしたものか確定することができません。そのため、各チャネルの出力に何が来るかは神のみぞ知る状況となります。
本研究では、誤差が最小となる組み合わせで推論した信号の和で、誤差逆伝播を行うことで信号分離を実現しています。
誤差関数
誤差関数は以下のとおりです。は原信号、
は推論した信号です。
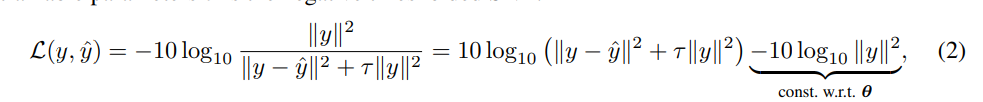
のL2ノルムが0になる場合が誤差が最小となる条件です。
は誤差関数をクランプするための定数で論文では [tex: \tau = 10^{-SNR{max}/10}]、 [tex: SNR{max}=30dB]としています。
モデル構造
TDCN++[2]を使用しているそうです。 TDCN++はConv-TasNet[3]を改良したモデルです。 詳しくは多分実装編を書くので、そのときにでもご紹介します。
[2] I. Kavalerov et al., “Universal sound separation,” IEEE Work. Appl. Signal Process. to Audio Acoust., vol. 2019-Octob, pp. 175–179, 2019, doi: 10.1109/WASPAA.2019.8937253. [3] Y. Luo and N. Mesgarani, “Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 27, no. 8, pp. 1256–1266, 2019, doi: 10.1109/TASLP.2019.2915167.
結果
デモがあるのでぜひ。Unsupervisedでもここまでできるのかと驚きました。 universal-sound-separation.github.io
そのうち実装したい。
aesthetic-predictorをパッケージにした
LAION-AIが開発したモデルの一つであるaesthetic-predictorというものがある。
github.com
画像の美しさを評価するモデルで、以下のような結果が得られるらしい。
データセット作りに便利そうなので今回パッケージにした。
CLIPとaestheticを推論するモデルを自動でダウンロードするようになっている。
github.com
導入はコマンド1つ。
pip install aesthetic_predictor
使い方は以下の通り。簡単だね。
from aesthetic_predictor import predict_aesthetic from PIL import Image print(predict_aesthetic(Image.open("path/to/image")))
pydanticからArgumentParserを作るライブラリをアップデートした
少し前に書いたライブラリであるpydantic-argparse-builderをアップデートした。
ライブラリの詳細については以下にまとめています。
qiita.com
もともと備えている機能は事前定義されているpydanticのオブジェクトにもとづいてPython標準のArgumentParserに引数を追加するだけでした。
しかし、人類は怠惰なので、ArgumentParserさえも内包してしまおうという考えに基づいて実装しています。
実装例は以下のとおりです。
from pydantic import BaseModel from pydantic_argparse_builder import command, main class Config(BaseModel): name: str age: int is_active: bool @command def launch(config: Config): print(config) if __name__ == "__main__": main()
上記は以下のコードと等価です。
from argparse import ArgumentParser from pydantic import BaseModel from pydantic_argparse_builder import build_parser class Config(BaseModel): name: str age: int is_active: bool def main(): parser = ArgumentParser() build_parser(parser, Config) args = parser.parse_args() launch(Config(**vars(args))) def launch(config: Config): print(config) if __name__ == "__main__": main()
このようにいい感じに短くできるのでやや使い勝手が向上するはずです。
もちろん、従来どおりの上記のような書き方もできるので、他のArgumentParserを拡張するライブラリとの併用や複雑なユースケースにも容易に対応することができます。
RustからWhisperを使ってみる
Rustで音声認識
はじめに
今回はWhisperを用いて音声認識を行います。 オリジナルのWhisperはPythonを使って実装されていますが、世の中にはWhisperをCで実装したライブラリwhisper.cppがあります。 さらに、それをRustで使うためにラッピングしたライブラリwhisper-rsを用いることになります。
Whisperとは
WhisperはOpenAIが開発した汎用的な音声認識モデルです。 多様な音声の大規模データセットで学習され、音声翻訳や言語識別だけでなく、多言語音声認識を行うことができるマルチタスクモデルでもあります。
したがって、今回の用途である音声認識以外にも認識言語の検出なども行える、非常に多機能なモデルとなっています。
ソースコードとモデルの重みは公開されており、簡単に使用できるようになっています。
Whisper.cppを使う上での注意点
Whisper.cppは以下の制限があります。
- モノラル、32bit float PCMしか対応していないため、例えば、一般的な16bit 整数、ステレオ音声を入力すると意図しない結果が得られる。
- モデルのデータはPyTorch標準のpt形式ではなく、独自のGGML形式で保存されている。
1点目はWhisper-rsに備え付けの関数を用いることで容易に対応することができます。
2点目のGGML形式のモデルはwhisper.cppのmodelsフォルダにあるdownload-ggml-modelsスクリプトを実行することでダウンロードできます。 Windowsであれば、download-ggml-models.cmd, Linuxであれば、download-ggml-models.shを実行することでダウンロードできます。
Whisper-rsを使う
Whisper-rsのexamplesにはファイルを読み込んで使う例はありません。
今回はrodioを使ってmp3ファイルを読み出して、Whisperによって音声認識するところまでをお試ししてみます。
use whisper_rs::{FullParams, SamplingStrategy, WhisperContext}; // 認識したスクリプトを保存する構造体 pub struct ScriptSegment { pub script: String, pub start: i64, pub end: i64, } // 認識機能のinterface pub trait Scripter { fn parse(&mut self, audio_data: &[f32]) -> Vec<ScriptSegment>; } // Whisper実装 pub struct WhisperScripter { ctx: WhisperContext, } impl WhisperScripter { fn new(model_path: &str) -> Self { WhisperScripter { ctx: WhisperContext::new(model_path).expect("Failed to load model"), } } } impl Scripter for WhisperScripter { fn parse(&mut self, audio_data: &[f32]) -> Vec<ScriptSegment> { let mut params = FullParams::new(SamplingStrategy::Greedy { n_past: 0 }); params.set_language("ja"); self .ctx .full(params, audio_data) .expect("Failed to recognize audio."); let num_segments = self.ctx.full_n_segments(); let mut scripts = Vec::new(); for i in 0..num_segments { scripts.push(ScriptSegment { script: self .ctx .full_get_segment_text(i) .expect("failed to get segment"), start: self.ctx.full_get_segment_t0(i), end: self.ctx.full_get_segment_t1(i), }); } scripts } } #[cfg(test)] mod tests { use rodio; use std::io::BufReader; use crate::scripter::*; #[test] fn test_whisper_scripter() { // mp3を読み出し・デコード let file = std::fs::File::open("assets/example-audio/common_voice_ja_31833274.mp3").unwrap(); let decoder = rodio::Decoder::new(BufReader::new(file)).unwrap(); let data = decoder.into_iter().collect::<Vec<i16>>(); // Whisperで使えるように変換(i16->f32) let data = whisper_rs::convert_stereo_to_mono_audio(&whisper_rs::convert_integer_to_float_audio(&data)); assert!(!data.is_empty()); // 音声認識 let scripts = WhisperScripter::new("assets/model/ggml-tiny.bin").parse(&data); assert!(!scripts.is_empty()); // let ans = "人類学者のいう所によれば、原始社会の生産作用も広義において法律的に支配せられているのである。" let mut all_script = "".to_owned(); for script in scripts { all_script.push_str(&script.script); } assert!( all_script.contains("人類学者") || all_script.contains("原始社会") || all_script.contains("支配") ); } }
debugpyがいい感じなことに気づいた
なにがあったか
docker-composeで立ち上げたpythonコンテナをデバッグするときに、VSCodeからDockerで立ち上げたコンテナにattachしてデバッグするのが面倒だと思っていた。
普通にフォルダが表示されるまで時間がかかるし、ソースコードを削除しているコンテナの場合、追加でボリュームをマウントしてとかの作業も発生する。
(このあたりも実はdevcontainer.jsonとかに書けば自動でやってくれるのかな)
生産性が低いのでなんとかしたいと思っていて、VSCodeのドキュメントを読み返していた。
解法
以下は簡単なサンプルコード
github.com
やっていることとしては、docker-compose.debug.yamlを>|-f|<オプションに与えることで、既存の設定を置き換えている。
主な変更点は下記
- entrypointを専用の実行スクリプトで置き換える(debugpyのインストールとdebupyのサーバを実行)
- 専用の実行スクリプトをDocker volumeでマウント
- ポート5678番をホストと共有(debugpyの通信用)
Dockerfileでentrypointを定義している場合もdocker-composeから置き換えるので、release用のコードを変更する必要は全くない。
また、Release用のコンテナではコンテナ容量削減のためにインストールに使ったPythonソース等を削除することは(pip installとかでフォルダをまるごとインストールされたパッケージを`python -m module_name`とかで実行するような使い方)
自分調べではよくやられていると思うが、この場合、深層にあるソースコードをわざわざ探しに行く羽目になるが、それははっきり言って大変なので避けたい。
これについてもDocker volumeでソースディレクトリをコンテナ内のカレントディレクトリにマウントしてやれば良い気がする。
>|python -m module_name|<とするとインストールしたパッケージではなくカレントディレクトリのモジュールがインポートされてそのままデバッグされるはずだ。
まとめ
debugpyは神**。
【Python】システムのSSL証明書の設定を読み出す【Windows】
今回はWindowsでOSで設定されているSSL証明書をPythonのライブラリで使用する方法について説明する。
PythonではSSL証明書を通常`certifi`というライブラリに埋め込まれたものを使用する。
そのため、OSに設定されているSSL証明書やそれ以外の証明書を使う方法はライブラリ毎に決められている方法に沿った方法を取る必要がある。
それは面倒なので、世の中にはそういう便利なものを作ってくれている人がいる。
Win32 API経由でシステムのSSL証明書を読み出し、それをPEM形式で保存。さらに、certifiの変数を書き換えることで、証明書の設定を行っている。
Proxyを使っている会社では`requests`を使うだけでも`SSLError`が出る。
意外と調べても出てこなかったので、備忘録として残しておく。