[論文紹介]Unsupervised Sound Separation Using Mixture Invariant Training
久々に、ブログを書く気になったので、最近読んでいて面白かった「Unsupervised Sound Separation Using Mixture Invariant Training」についてまとめる。 特に記載がなければ論文中の図表は以下を参照しています。
[1] S. Wisdom, E. Tzinis, H. Erdogan, R. J. Weiss, K. Wilson, and J. R. Hershey, “Unsupervised sound separation using mixture invariant training,” Adv. Neural Inf. Process. Syst., vol. 2020-Decem, no. NeurIPS, 2020. https://proceedings.neurips.cc/paper/2020/file/28538c394c36e4d5ea8ff5ad60562a93-Paper.pdf
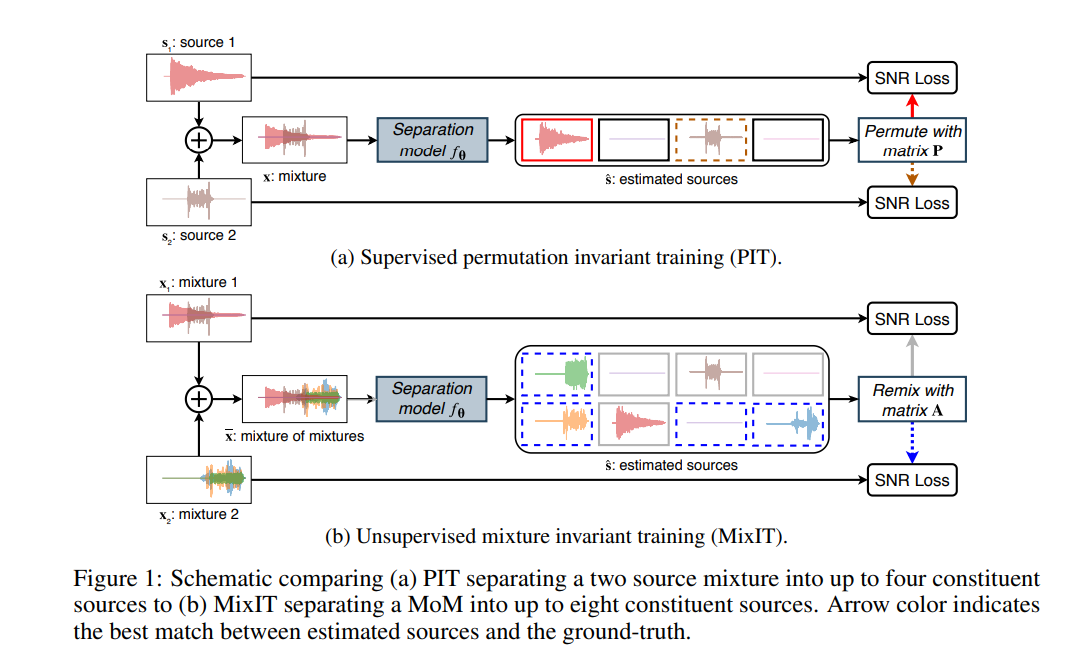
もうちょっと自分の理解を備忘録としてまとめたい。
そもそもこの論文なに?
Blind Source SeparationとかBlind Singnal Separationというジャンルの論文です。 Mixされた信号からMixする前の信号(原信号)を分離することを目標としていて、特に、この論文ではUnsupervised learningで実現することを目標としています。 UnsupervisedなBlind Source Separation問題で典型的な問題としてモデルの入力であるMixされた信号の原信号がどのようになっているかは知ることができません。 そのため学習のさせ方そのものを工夫しているのが本論文です。
学習のさせ方
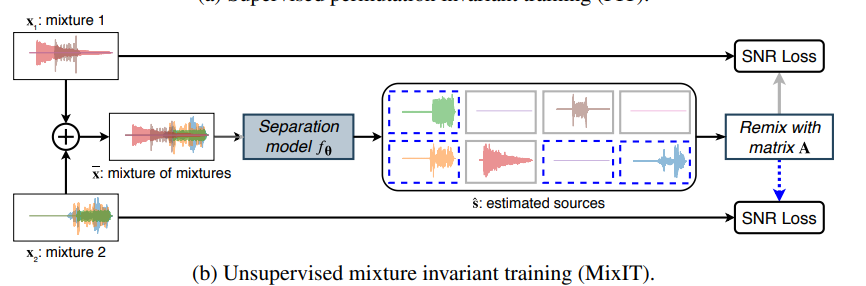 一枚目にも書いていますがUnsupervisedな部分だけ再掲。
要は学習データ2個の和をとった信号をモデルに入力して、出力はその信号を分離した信号になります。
分離する個数は感覚で決めることになると思います。
一般的なデータの入出力テンソルの形状は入力が(N, 1)、出力が(N, C)となります(特にNは信号の系列長、Cは分離する信号の数=チャネル数)。
一枚目にも書いていますがUnsupervisedな部分だけ再掲。
要は学習データ2個の和をとった信号をモデルに入力して、出力はその信号を分離した信号になります。
分離する個数は感覚で決めることになると思います。
一般的なデータの入出力テンソルの形状は入力が(N, 1)、出力が(N, C)となります(特にNは信号の系列長、Cは分離する信号の数=チャネル数)。
ここで、1つ問題があります。 分離した信号の出力は出力信号の入れ替わりが起こり得ます。
例えば、このとき、出力の各チャネルのどこに何を分離するかはSupervised Learningでは一意に決めることができますが(例えば環境音+人の話し声なら、1チャネル目に環境音、2チャネル目に人の話し声を入れたデータを学習データとして用意して誤差計算を行う)、Unsupervised Learningでは入力データがどのような音をMixしたものか確定することができません。そのため、各チャネルの出力に何が来るかは神のみぞ知る状況となります。
本研究では、誤差が最小となる組み合わせで推論した信号の和で、誤差逆伝播を行うことで信号分離を実現しています。
誤差関数
誤差関数は以下のとおりです。は原信号、
は推論した信号です。
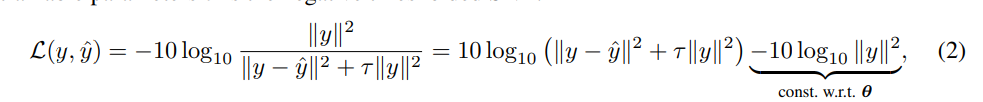
のL2ノルムが0になる場合が誤差が最小となる条件です。
は誤差関数をクランプするための定数で論文では [tex: \tau = 10^{-SNR{max}/10}]、 [tex: SNR{max}=30dB]としています。
モデル構造
TDCN++[2]を使用しているそうです。 TDCN++はConv-TasNet[3]を改良したモデルです。 詳しくは多分実装編を書くので、そのときにでもご紹介します。
[2] I. Kavalerov et al., “Universal sound separation,” IEEE Work. Appl. Signal Process. to Audio Acoust., vol. 2019-Octob, pp. 175–179, 2019, doi: 10.1109/WASPAA.2019.8937253. [3] Y. Luo and N. Mesgarani, “Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation,” IEEE/ACM Trans. Audio Speech Lang. Process., vol. 27, no. 8, pp. 1256–1266, 2019, doi: 10.1109/TASLP.2019.2915167.
結果
デモがあるのでぜひ。Unsupervisedでもここまでできるのかと驚きました。 universal-sound-separation.github.io
そのうち実装したい。